7.6. ML 1¶
7.6.1. 与AI:raw-latex:DL:raw-latex:`Data `Mining等的关系¶
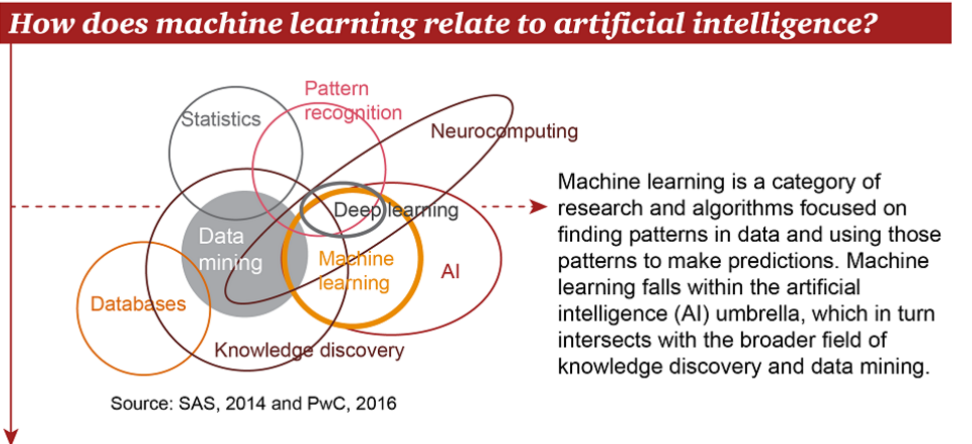
Fig. 7.6.1 与AI:raw-latex:DL:raw-latex:`\Data `Mining等的关系\ `10 <http://www.mysecretrainbow.com/ai/17264.html>`__¶
7.6.2. 类别¶
第一类是构造间隔理论分布:聚类分析和模式识别
人工神经网络
决策树
感知器
支持向量机
集成学习AdaBoost
降维与度量学习
聚类
贝叶斯分类器
第二类是构造条件概率:回归分析和统计分类
高斯过程回归
线性判别分析
最近邻居法
径向基函数核
第三类是通过再生模型构造概率密度函数
最大期望算法
概率图模型:包括贝叶斯网和Markov随机场
Generative Topographic Mapping
第四类是近似推断技术
马尔可夫链
蒙特卡罗方法
变分法
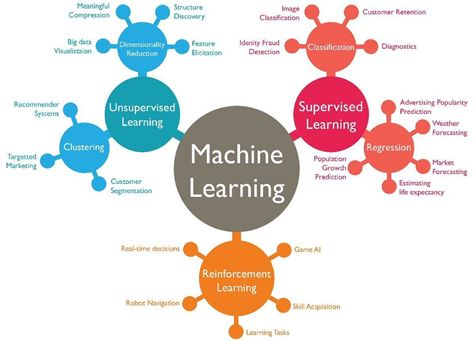
7.6.3. ML VS software engineering¶
术语“软件工程”第一次出现是在1965年,也就是编程语言开始出现的15年后。大约20年后,软件工程研究所成立,以管理软件工程过程。今天,我们已经普遍接受了软件工程的最佳实践。另一方面,机器学习直到20世纪90年代才作为一个独立的领域开始蓬勃发展。深度学习是ML的一个子集,它在许多问题上的准确性创造了新纪录,包括图像识别和自然语言处理,直到2012年AlexNet的兴起才被广泛讨论。与软件工程相比,ML仍处于起步阶段,因此缺乏行业标准、度量标准、基础设施和工具。公司仍在探索最佳实践,扼杀应用程序。5
7.6.4. 选择¶
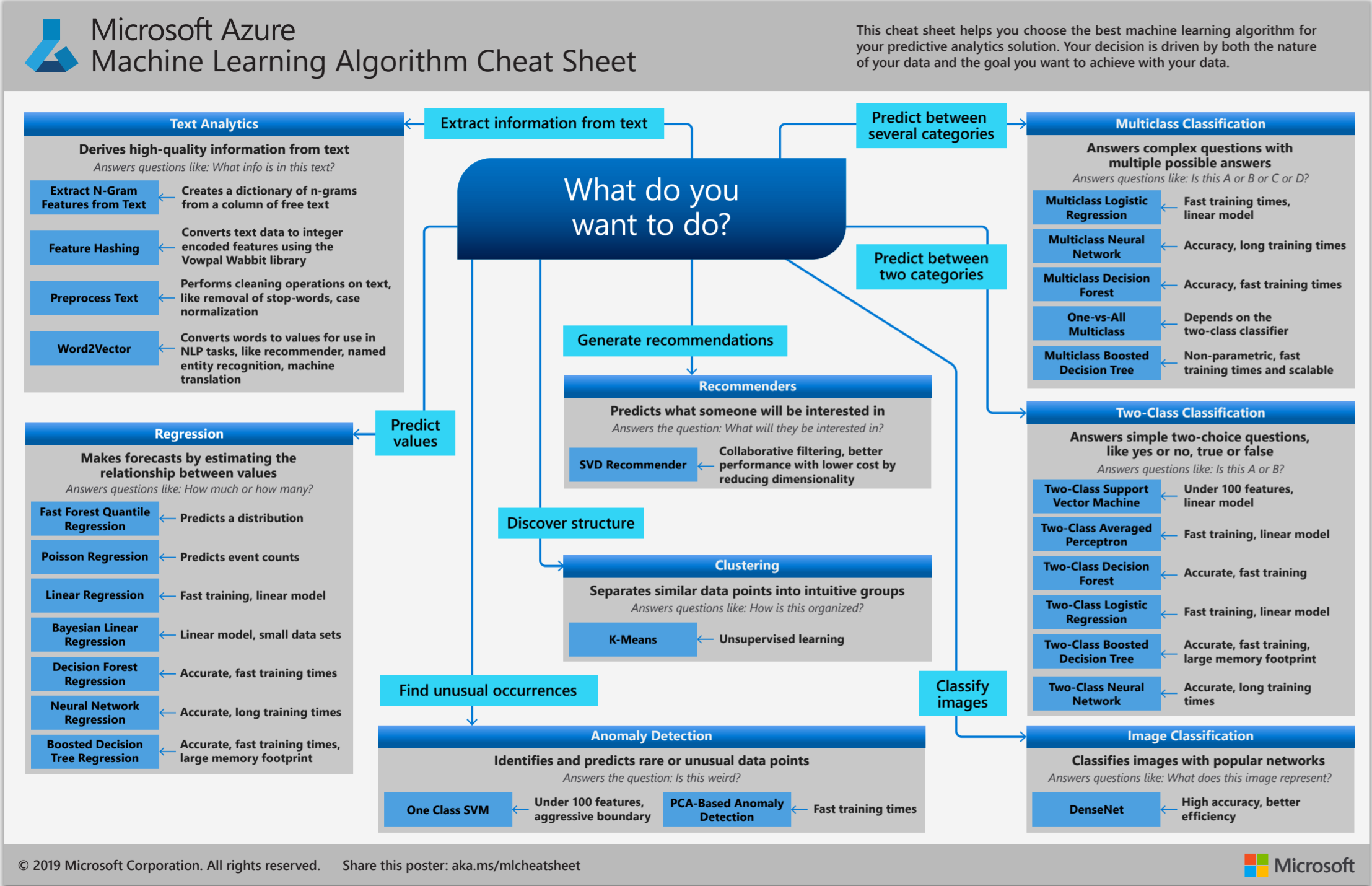
如何选择?9
在具体算法选择上,基于Python的scikit-learn机器学习算法库提供一套算法选择方法,参考这一部分(不局限于图中的算法和方法,由于这张图大多考虑了scikit中算法的实现情况)具体介绍一下算法的选择如下: 4
首先统计数据的容量当数据过小(小于50条)时,建议收集更多的数据,因为过小的数据训练的算法容易受噪声的影响比较大,算法效果一般。
判断是否为预测一个类别的问题,如果是并且训练数据中包含标签信息则为分类问题。
如果是预测一个类别的问题但是训练数据中不包含标签信息则是一个聚类问题
如果不是一个分类问题,是预测一个具体的数值问题一般为回归问题,如果不是预测具体数值对数据进行分析,挖掘数据中的异常值等问题,这时可以考虑一下是否为降维问题。
对于分类问题,如果数据量小于100k,建议用线性SVM的方法,如果效果不好根据是否为文本信息考虑用贝叶斯方法或者K临近分类法。如果数据量过大可以考虑加入正则化的方法来防止过拟合的问题来保证模型的稳定性。
对于聚类问题,如果我们知道需要划分的数据集个数一般使用Kmeans等聚类方法即可。如果无法获知聚类的个数一般使用mean-shift的基于密度的算法可以对模型进行聚类评估,
对于回归问题,如果数据量不大,直接使用SVM之类的回归即可,当然如果数据量过大可以考虑使用L1,L2的正则化方法来对权值进行正则化来防止过拟合问题的出现。这部分算法的选择与分类问题很相似。
对于降维问题,如果是考虑为分类问题的输入维度进行削减,一般考虑LDA方法可以很好的对每个类别上的数据进行降维处理。如果单纯对输入维度进行降维,将原有维度信息转移到新的维度(根据维度的正交化来达到降维的目的)一般使用PCA方法是比较主流的方法。
对于算法的选择,有时不能找到确定的方法,也就是说很难根据数据是使用场景就完全锁定了那一个具体的算法,但是根据却可以缩小到指定的几个常用算法。然后通过测试集和训练集在这几个算法上做一些Demo。根据Demo反应的质量决定最终使用的算法那个。看似比较费力,其实是比较稳妥和精准的方法。
7.6.5. 机器学习框架 6¶
机器学习方面的新框架层出不穷,一方面我们需要掌握经典框架的使用方式,理解其模块构成,接口规范的设计,一定程度上来说其它新框架也都需要遵循这些业界标准框架的模块与接口定义。另一方面对于新框架或特定领域框架,我们需要掌握快速评估,上手使用,并且做一定改造适配的能力。一些比较经典的框架有:
通用机器学习:scikit-learn,Spark ML,LightGBM
通用深度学习:Keras/TensorFlow,PyTorch
特征工程:tsfresh, Featuretools,Feast
AutoML:hyperopt,SMAC3,nni,autogluon
可解释机器学习:shap,aix360,eli5,interpret
异常检测:pyod,egads
可视化:pyecharts,seaborn
数据质量:cerberus,pandas_profiling,Deequ
时间序列:fbprophet,sktime,pyts
大规模机器学习:Horovod,BigDL,mmlspark
Pipeline:MLflow, metaflow,KubeFlow,Hopsworks
一般的学习路径主要是阅读这些框架的官方文档和tutorial,在自己的项目中进行尝试使用。对于一些核心接口,也可以阅读一下相关的源代码,深入理解其背后的原理。

7.6.6. 指标¶
准确率(P值)是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。
召回率(R值)是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。
7.6.7. 更多¶
https://mitpress.ublish.com/ereader/7093/?preview=#page/v
《美团机器学习实践》笔记:https://www.dazhuanlan.com/2019/10/17/5da8114a3b457/
至少你要知道什么是二分类问题,什么是ground truth、熵(entropy)的概念,dynamic learning的概念等等。2
不容错过的 20 个机器学习与数据科学网站11
7.6.8. 技术债务¶
“技术债务”,指为了产品快速迭代,做了很多临时性的代码处理。但是在未来的某一天,这些遗留问题都会以BUG方式体现出来,导致付出更大的维护成本14
技术债务或许可以通过重构代码,改善单元测试,删除僵尸代码,减少依赖,精简 API 和改良文档说明进行清算。其目的不在于添加新功能,而是着眼于未来的提升,减少错误和提高可维护性。延期偿还只会加重负担,隐性债务之所以危险正是因为它是悄无声息间积攒下的。12
7.6.9. ML system¶
机器学习系统在以下方面与其他软件系统不同:13
团队技能:在机器学习项目中,团队通常包括数据科学家或机器学习研究人员,他们主要负责进行探索性数据分析、模型开发和实验。这些成员可能不是经验丰富的、能够构建生产级服务的软件工程师。
开发:机器学习在本质上具有实验性。您应该尝试不同的特征、算法、建模技术和参数配置,以便尽快找到问题的最佳解决方案。您所面临的挑战在于跟踪哪些方案有效、哪些方案无效,并在最大程度提高代码重复使用率的同时维持可重现性。
测试:测试机器学习系统比测试其他软件系统更复杂。除了典型的单元测试和集成测试之外,您还需要验证数据、评估经过训练的模型质量以及验证模型。
部署:在机器学习系统中,部署不是将离线训练的机器学习模型部署为预测服务那样简单。机器学习系统可能会要求您部署多步骤流水线以自动重新训练和部署模型。此流水线会增加复杂性,并要求您自动执行部署之前由数据科学家手动执行的步骤,以训练和验证新模型。
生产:机器学习模型的性能可能会下降,不仅是因为编码不理想,而且也因为数据资料在不断演变。换句话说,与传统的软件系统相比,模型可能会通过更多方式衰退,而您需要考虑这种降级现象。因此,您需要跟踪数据的摘要统计信息并监控模型的在线性能,以便系统在值与预期不符时发送通知或回滚。
More15